
Backend GraphQL: How to trigger an AWS AppSync mutation from AWS Lambda
This blog will explore a technique that opens up a whole new world of possibilities for notifying clients of results within a serverless application.
Let’s say you have built a nice mobile and web versions of a chat application that uses a GraphQL API built on top of AWS AppSync.
- Users authenticate with Amazon Cognito user pools
- Users table is stored in DynamoDB
- Changes to the users table are communicated to the app via subscriptions
How does the users table get updated?
A naive approach would be to get the clients to perform a mutation against the users table immediately after authentication. The client can just store their userId and any other user details you see fit through an addUser mutation.
However, this creates a security issue with a bad actor — and there are always bad actors — who could sign in as one user and then pretend to be another.
To get around this security issue, a developer could create the addUser mutation to obtain the userId from the authentication information — thus allowing you to secure the information.
There is another method — and the technique demonstrates a mechanism for a whole new slew of useful features.
A developer can define an AWS Lambda function that is triggered after the user has authenticated with Amazon Cognito user pools, and then automatically calls the mutation behind the scenes.
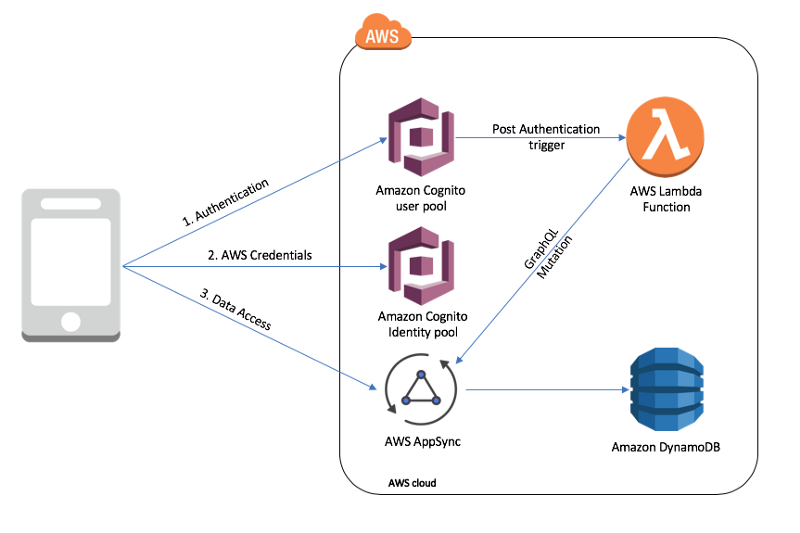
The slew of new possibilities with this technique include:
- When an image is uploaded, automatically run it through Amazon Rekognition for automated tagging, calling a mutation with the new tags when it’s finished.
- When a video is uploaded, automatically transcribe the video so that you can search on the words spoken within the video. When the transcribe process has finished, call a mutation with the transcribed text.
- When you are bulk loading data into a database, call a mutation to notify the users that the database needs to be completely refreshed.
- If you perform a daily training on machine learning data, call a mutation to notify the users that the new machine learning data can be downloaded.
Basically, whenever you need to do something server-side but notify the users, you can call a mutation to trigger subscription notifications to your clients. This is a very powerful feature. It’s also not that complicated to set up.
- If you are not using the
AWS_IAMauthentication type, you will need to convert to usingAWS_IAM. - Add the mutation to your GraphQL schema.
- Add a policy to the authenticated role that allows users to access only the user mutations.
- Add a role for your Lambda function that allows the function to access the new mutation.
- Write a Lambda function that calls the mutation.
None of this is particularly hard, especially when you use the Serverless Framework to configure everything. GraphQL is “just” a HTTP POST with a payload, so you don’t even need a library.
Step 1: Convert to using AWS_IAM
If you have configured your GraphQL API to use Amazon Cognito user pools, it’s likely that you have bypassed IAM. That won’t work when the backend resources need to access the GraphQL API. You have to use AWS_IAM.
To do that, you need to create an authenticated and unauthenticated role, then create an Amazon Cognito identity pool and link the roles you just created to the identity pool. This will also involve changing the authentication mechanism within your client applications.
In Serverless Framework, this is defined in the Resources section of the serverless.yml file. First, let’s configure an Amazon Cognito user pool:
CognitoUserPoolMyPool:
Type : AWS::Cognito::UserPool
Description : "Username / Password auth database"
Properties:
UserPoolName : ${self:provider.apiname}
Schema:
- Name : email
Required : true
Mutable : true
Policies:
PasswordPolicy:
MinimumLength : 6
RequireLowercase : false
RequireUppercase : false
RequireNumbers : false
RequireSymbols : false
AutoVerifiedAttributes : [ "email" ]
MfaConfiguration : "OFF"
AndroidUserPoolClient:
Type : AWS::Cognito::UserPoolClient
Description : "OAuth2 app client for Android app"
Properties:
ClientName : ${self:provider.apiname}-android
GenerateSecret : true
UserPoolId : { Ref: CognitoUserPoolMyPool }
Note that an Amazon Cognito user pool logical ID must always start with the string CognitoUserPool if you want to use it when defining triggers. Now, let’s define the two roles we will need:
AuthRole:
Type : AWS::IAM::Role
Description : "Role that the an authenticated user assumes"
Properties:
RoleName : ${self:provider.apiname}-auth
AssumeRolePolicyDocument:
Version : "2012-10-17"
Statement:
- Effect : Allow
Principal:
Federated : cognito-identity.amazonaws.com
Action : sts:AssumeRoleWithWebIdentity
Condition:
ForAnyValue:StringLike:
"cognito-identity.amazon.com:amr": "authenticated"
UnAuthRole:
Type : AWS::IAM::Role
Description : "Role that the an authenticated user assumes"
Properties:
RoleName : ${self:provider.apiname}-unauth
AssumeRolePolicyDocument:
Version : "2012-10-17"
Statement:
- Effect : Allow
Principal:
Federated : cognito-identity.amazonaws.com
Action : sts:AssumeRoleWithWebIdentity
Condition:
ForAnyValue:StringLike:
"cognito-identity.amazon.com:amr": "unauthenticated"
These are the basic role definitions for authenticated and unauthenticated identities. They don’t actually give you permissions to access any resources. You need to attach policies to these to allow the users to access AWS services (which we will do later).
Now, let’s create the identity pool:
IdentityPool:
Type : AWS::Cognito::IdentityPool
Description : "Federation for the User Pool members to access AWS resources"
Properties:
IdentityPoolName : ${self:provider.apiname}_identities
AllowUnauthenticatedIdentities : true
CognitoIdentityProviders:
- ClientId : { Ref: AndroidUserPoolClient }
ProviderName : { Fn::Sub: [ 'cognito-idp.${self:provider.region}.amazonaws.com/#{client}', { "client": { Ref: CognitoUserPoolMyPool }}]}
IdentityPoolRoleMap:
Type : AWS::Cognito::IdentityPoolRoleAttachment
Description : "Links the unauthenticated and authenticated policies to the identity pool"
Properties:
IdentityPoolId : { Ref: IdentityPool }
Roles:
unauthenticated : { Fn::GetAtt: [ UnAuthRole, Arn ]}
authenticated : { Fn::GetAtt: [ AuthRole, Arn ]}
Identity pools consist of two parts:
- The first tells the identity pool what identity providers to federate. In this case, I only have one — the Amazon Cognito user pool. You can also add Facebook, Google, or other OIDC providers, or SAML providers like Active Directory Federated Services.
- The second part tells the identity pool what IAM roles to assign to the users once they are authenticated.
The final step in the process is to change your GraphQL API to be AWS_IAM. I am using the serverless-appsync-plugin, which makes it easy:
custom:
appSync:
name: ${self:provider.apiname}
region: ${self:provider.region}
authenticationType: AWS_IAM
serviceRole: "AppSyncServiceRole"
The good news is that this is all pretty much boiler-plate. Take it as a single snippet and integrate it into your serverless.yml whenever you need to use federated identities.
Make sure you also update your client to use AWS_IAM and an authentication process that uses the identity pool. If you are using AWS Amplify, the library will take care of it for you once you change your configuration.
Step 2: Add a mutation to your GraphQL schema
Since I am using the serverless-appsync-plugin, this is easy. I have to add something to my schema.graphql file:
type Mutation {
addUser(userId: ID!, userDetails: UserInput): User
updateUser(userDetails: UserInput!): User
}
type Subscription {
userUpdates: User
@aws_subscribe(mutations: ["addUser", "updateUser"])
}
While you are here, remove any @aws_auth decorators. The @aws_auth decorator only applies to the Amazon Cognito user pool, and we are not using that directly any more. I added the addUser() mutation for the Lambda to call. It will not be available to users.
I also added the mutation to the list of mutations in the @aws_subscribe decorator so that both changes via the Lambda and changes from the user (for example, setting their full name) will be communicated to all clients, allowing every client to maintain the user list in real time.
The mapping templates should do “what is required”. In my case, I want to add or update the user record in the users table within DynamoDB. The request mapping looks like this:
{
"version": "2017-02-28",
"operation": "PutItem",
"key": {
"userId": $util.dynamodb.toDynamoDBJson($ctx.args.userId)
},
"attributeValues": $util.dynamodb.toMapValuesJson($ctx.args.userDetails)
}
It is linked into the GraphQL API using the serverless-appsync-plugin:
- type : Mutation
field : addUser
dataSource : "UsersTable"
request : "addUser-request.vtl"
response : "single-response.vtl"
Step 3: Add policy to the authenticated role
I want authenticated users to be able to access all the queries and subscriptions and all the mutations except for the addUser mutation.
To do this, I will adjust the AuthRole as follows:
AuthRole:
Type : AWS::IAM::Role
Description : "Role that the an authenticated user assumes"
Properties:
RoleName : ${self:provider.apiname}-auth
AssumeRolePolicyDocument:
Version : "2012-10-17"
Statement:
- Effect : Allow
Principal:
Federated : cognito-identity.amazonaws.com
Action : sts:AssumeRoleWithWebIdentity
Condition:
ForAnyValue:StringLike:
"cognito-identity.amazon.com:amr": "authenticated"
Policies:
- PolicyName : ${self:provider.apiname}-auth-appsync
PolicyDocument:
Version : "2012-10-17"
Statement:
- Effect : Allow
Action : appsync:GraphQL
Resource:
- { Fn::Join: [ '', [ { Ref: GraphQlApi }, '/types/Query/fields/*' ] ] }
- { Fn::Join: [ '', [ { Ref: GraphQlApi }, '/types/Subscription/fields/*' ] ] }
- { Fn::Join: [ '', [ { Ref: GraphQlApi }, '/types/Mutation/fields/updateUser' ] ] }
There are a couple of things to note here. The permissions you give to an authenticated user are defined in the Policies section. This is an array of policy documents, so you can add multiple policies for multiple services here.
With the serverless-appsync-plugin, the GraphQL API ARN is provided with {Ref: GraphQlApi } — this has a side-effect that you can only have one GraphQL API, which is definitely the best practice. You don’t want multiple doors to your backend to secure. I am allowing all the queries and subscriptions here, but explicitly listing the mutations that the user is allowed to perform.
You can do the same thing with unauthenticated users by altering the UnauthRole, which enables you to finely control what users can and cannot do.
Step 4: Add a role for the Lambda function
The final bit is that I need an IAM role that will allow my Lambda function to access the AWS AppSync API:
PostAuthenticationRole:
Type : AWS::IAM::Role
Properties:
RoleName : ${self:provider.apiname}-postauth-lambda
AssumeRolePolicyDocument:
Version : "2012-10-17"
Statement:
- Effect : Allow
Principal:
Service: lambda.amazonaws.com
Action : sts:AssumeRole
Policies:
- PolicyName : ${self:provider.apiname}-postauth-appsync
PolicyDocument:
Version : "2012-10-17"
Statement:
- Effect: Allow
Action: appsync:GraphQL
Resource: { Fn::Join: [ '', [ { Ref: GraphQlApi }, '/types/Mutation/fields/addUser' ] ] }
- PolicyName : ${self:provider.apiname}-postauth-cloudwatch
PolicyDocument:
Version : "2012-10-17"
Statement:
- Effect : Allow
Action : logs:CreateLogGroup
Resource: "arn:aws:logs:${self:provider.region}:#{AWS::AccountId}:*"
- Effect : Allow
Action : [ logs:CreateLogStream, logs:PutLogEvents ]
Resource: "arn:aws:logs:${self:provider.region}:#{AWS::AccountId}:log-group:/aws/lambda/${self:service}-${self:provider.stage}-postAuthentication:*"
I am only allowing the Lambda function to access a single mutation — the addUser mutation. This mutation is not available to the users — as we explicitly did not list it in the AuthRole previously.
I like the principal of minimal access for security. I am not expecting the Lambda to perform queries or subscriptions, so why should I give permissions to the Lambda to perform them?
Note that you also need to include the policies from the Basic Execution Role for AWS Lambda. These enable CloudWatch logging for the function. If you do not include these, then you won’t be able to do any logging to CloudWatch.
Step 5: Write a Lambda function
All this set up has been leading to this. How do I write a Lambda function to execute a mutation? Well, first off, let’s define a Lambda function within serverless.yml that will be triggered on the post authentication step:
provider:
name : aws
region : us-east-1
runtime : nodejs8.10
stage : ${opt:stage, 'dev'}
apiname : ${opt:apiname, 'chatql'}_${self:provider.stage}
environment:
GRAPHQL_API : { Fn::GetAtt: [ GraphQlApi, GraphQLUrl ] }
REGION : ${self:provider.region}
functions:
postAuthentication:
handler : cognito.postauth
role : PostAuthenticationRole
events:
- cognitoUserPool:
pool : MyPool
trigger : PostAuthentication
What does this do?
- The function itself is defined in a file called
cognito.jsand thepostauthexport will be executed when triggered. - The function will be triggered by an event on the Amazon Cognito user pool. The pool is listed as
MyPool, but defined asCognitoUserPoolMyPool(yeah — this made no sense to me either). - The functions will have two environment variables — the
GRAPHQL_APIwill contain the URL to the GraphQL endpoint and theREGIONwill contain the region that the GraphQL endpoint is located in.
The Serverless Framework will bundle all the relevant files for us and deploy the function. Now, let’s take a look at my first look at the cognito.js file:
const env = require('process').env;
exports.postauth = (event, context, callback) => {
console.log("Authentication successful");
console.log(`Event = ${JSON.stringify(event, null, 2)}`);
console.log(`Context = ${JSON.stringify(context, null, 2)}`);
console.log(`Environment = ${JSON.stringify(env, null, 2)}`);
callback(null, event);
}
Really, all I am doing here is looking at a valid authentication event. I want to ensure that the environment is what I expect, and I want to take a look at the event that is passed to me. Once I authenticate, I’ll see something akin to the following for the event structure:
{
"version": "1",
"region": "us-east-1",
"userPoolId": "us-east-1_ABCDEFGH",
"userName": "myusername",
"callerContext": {
"awsSdkVersion": "aws-sdk-android-2.6.29",
"clientId": "androiduserpoolappclientid"
},
"triggerSource": "PostAuthentication_Authentication",
"request": {
"userAttributes": {
"sub": "user-guid",
"email_verified": "true",
"cognito:user_status": "CONFIRMED",
"name": "Adrian Hall",
"phone_number_verified": "false",
"phone_number": "+17205551212",
"email": "photoadrian@outlook.com"
},
"newDeviceUsed": false
},
"response": {}
}
You can check this for yourself in the CloudWatch logs. We need something like this because it allows us to test our Lambda function using the test facility within the AWS Lambda console:
- Click on Test, or drop down the list to the left of the Test button and choose Configure test events.
- Copy/paste the information you saw in your CloudWatch logs for the event into the editor.
- Give the test a name, then click Save.
You can now click the Test button to run the Lambda function as if the Amazon Cognito service had triggered it. This removes a reliance on the client application for testing.
The next question is “how do we trigger a mutation within AWS AppSync from a Lambda function”. Unfortunately, all client libraries — including AWS Amplify — rely on standard client authentication schemes for the GraphQL connectivity, and they rely on the existence and authentication to an Amazon Cognito Identity Pool.
When we are operating within AWS Lambda, we don’t authenticate since we are pre-authenticated. AWS Lambda gives us an IAM access key, secret key and session token within the environment for this purpose.
GraphQL is routed over HTTPS. That means we can simulate the GraphQL client libraries with a simple HTTPS POST. Since we are using IAM, we need to sign the request before we deliver it. Here is my code for this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
const env = require('process').env;
const fetch = require('node-fetch');
const URL = require('url');
const AWS = require('aws-sdk');
AWS.config.update({
region: env.AWS_REGION,
credentials: new AWS.Credentials(env.AWS_ACCESS_KEY_ID, env.AWS_SECRET_ACCESS_KEY, env.AWS_SESSION_TOKEN)
});
/**
* Amazon Cognito trigger for post-authentication
*
* @param {event} the details from the Amazon Cognito session about the user
* @param {context} the AWS Lambda context
* @param {callback} Function to call when we are done with processing.
*/
exports.postauth = (event, context, callback) => {
console.log(`Event = ${JSON.stringify(event, null, 2)}`);
console.log(`Env = ${JSON.stringify(env, null, 2)}`);
const AddUser = `mutation AddUser($userId: ID!, $userDetails: UserInput!) {
addUser(userId: $userId, userDetails: $userDetails) {
userId
name
}
}`;
const details = {
userId: event.request.userAttributes.sub,
userDetails: {
name: event.request.userAttributes.name
}
};
const post_body = {
query: AddUser,
operationName: 'AddUser',
variables: details
};
console.log(`Posting: ${JSON.stringify(post_body, null, 2)}`);
// POST the GraphQL mutation to AWS AppSync using a signed connection
const uri = URL.parse(env.GRAPHQL_API);
const httpRequest = new AWS.HttpRequest(uri.href, env.REGION);
httpRequest.headers.host = uri.host;
httpRequest.headers['Content-Type'] = 'application/json';
httpRequest.method = 'POST';
httpRequest.body = JSON.stringify(post_body);
AWS.config.credentials.get(err => {
const signer = new AWS.Signers.V4(httpRequest, "appsync", true);
signer.addAuthorization(AWS.config.credentials, AWS.util.date.getDate());
const options = {
method: httpRequest.method,
body: httpRequest.body,
headers: httpRequest.headers
};
fetch(uri.href, options)
.then(res => res.json())
.then(json => {
console.log(`JSON Response = ${JSON.stringify(json, null, 2)}`);
callback(null, event);
})
.catch(err => {
console.error(`FETCH ERROR: ${JSON.stringify(err, null, 2)}`);
callback(err);
});
});
}
You will need to add node-fetch and aws-sdk to the package.json:
npm install --save node-fetch aws-sdk
The parts of this:
- Lines 22–27 define the GraphQL operation we want to execute.
- Lines 29–34 define the variables for the GraphQL operation.
- Lines 36–40 construct the body of the HTTP POST that we need to send to a GraphQL server.
- Lines 44–49 use the AWS SDK to set up the HTTP request.
- Lines 51–53 sign the request with SIGv4.
- Lines 55–70 use WhatWG Fetch to send the POST request to the server, logging the response or error.
Right now, if the HTTP POST returns, then it is considered a success, which isn’t quite right. GraphQL can return the normal HTTP status codes. If there is an error, then you will get “success” but the object returned will have a list of errors. You should definitely deal with error handling appropriately.
Wrap up
This technique opens up a whole host of possibilities for notifying clients of results within a serverless application.
- Connect your clients to your backend via GraphQL.
- Let your clients subscribe to changes in the GraphQL API.
- Then use GraphQL mutations to communicate with them from within AWS Lambda.
Leave a comment