
Handling File Uploads with AWS AppSync
GraphQL does not handle files.
It may seem an obvious statement, but it needs to be said. GraphQL does not handle files. It handles structured data. Which isn’t to say that GraphQL does not have a role to play within file handling — just that the upload and download of files needs to be done outside the confines of GraphQL.
In this article, I’m going to present one way that you can handle the upload and download of files whereby the URL of the files are presented via GraphQL using AWS AppSync and the actual upload / download of the files are done via HTTP.
To do this, I’m going to implement a feature — profile pictures — in my Restaurant Reviews app. Any user can download a profile picture, but only the owner of a profile can upload the profile picture. Here is the architecture:
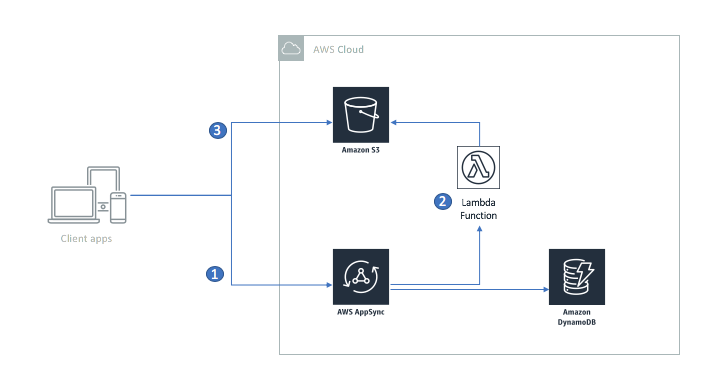
- The client app asks AWS AppSync (via GraphQL) for an upload URL.
- AWS AppSync invokes an AWS Lambda function to generate a pre-signed URL for upload purposes and returns it to the client. A pre-signed URL grants temporary permissions for the operation.
- The client app then uploads the file to the pre-signed URL.
A pre-signed URL is used to grant a user temporary credentials to perform an action on S3, such as to upload or download a file. It is not without its drawbacks (for example, all pre-signed URLs will expire and multi-part uploads are particularly problematic with pre-signed URLs), but for this use case, they are a great option.
To accomplish this, I have expanded my GraphQL schema as follows:
type S3Object {
bucket: String
key: String
region: String
url: AWSURL
uploadUrl: AWSURL
}
type User {
id: ID!
lastUpdated: AWSTimestamp
name: String
profilePicture: S3Object
# Rest of the User object goes here
}
The S3Object is the same S3Object mentioned within the AWS Amplify documentation when talking about complex file objects, so the response is compatible with the AWS Amplify libraries when they add support for complex objects. However, I have extended the S3Object by adding two fields to it for the pre-signed URLs. The profilePicture value will be resolved by the AWS Lambda function I mentioned earlier. The AWS Lambda function is fed a context that consists of a source (the user that is being handled) and identity (the user that is making the request).
- If
$context.source.id(the ID of the user being requested) is$context.identity.username(the ID of the user making the request), then return both a pre-signed upload URL and the download URL. - If not, then only return the download URL.
In addition, I will define an AWS Lambda function that sets the lastUpdated field for the user once uploading is complete.
With this model, we can do several things (aside from uploading the file):
- Subscribe to new profile pictures for a specific user.
- Do image manipulation on the picture prior to publishing (such as crop the image to just the face or re-size suitable for our application).
- Do machine learning tasks on the picture (for example, reject images that do not meet decency guidelines based on Amazon Rekognition).
Implementing the Data Storage Layer
Before we get to the Lambda functions, we need to create resources. I already have a configuration that includes AWS AppSync, Amazon Cognito user pools, and Amazon Cognito identity pools, plus some IAM roles. It is built using the Serverless Framework for repeatable deployments. Here is the Amazon S3 definition:
FileStorage:
Type: AWS::S3::Bucket
Properties:
CorsConfiguration:
CorsRules:
- AllowedOrigins:
- '*'
AllowedHeaders:
- '*'
AllowedMethods:
- GET
- PUT
MaxAge: 3000
In addition, we need to adjust permissions via IAM roles. Specifically:
- The AWS Lambda function needs permission to use
S3:GetObjectso that it can generate a pre-signed URL - All users (both authenticated and unauthenticated) need permission to
S3:GetObjectso that they can download the profile images. - Authenticated users need permission to
S3:PutObjectof their own image so that they can upload their own profile image.
I’m going to store the images with the key profilePictures/id.png within the S3 bucket where the id concerned is the id of the user. The AuthRole and UnauthRole definitions within my IAM roles provide the user permissions. For example, here is my new UnauthRole:
UnauthRole:
Type: AWS::IAM::Role
Properties:
RoleName: ${self:custom.api}-unauth
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Federated: cognito-identity.amazonaws.com
Action: sts:AssumeRoleWithWebIdentity
Condition:
ForAnyValue:StringLike:
"cognito-identity.amazonaws.com:amr": "unauthenticated"
Policies:
- PolicyName: AllowProfilePictureDownload
PolicyDocument:
Version: "2012-10-17"
Statement:
- Action:
- "s3:GetObject"
Effect: Allow
Resource:
- { Fn::GetAtt: [ FileStorage, Arn ]}
- { Fn::Join: [ "/", [{ Fn::GetAtt: [ FileStorage, Arn ]}, "*" ]]}
- PolicyName: AllowUnauthenticatedAppSyncQueries
PolicyDocument:
Version: "2012-10-17"
Statement:
- Action:
- "appsync:GraphQL"
Effect: Allow
Resource:
- { Fn::Join: [ "/", [{ Fn::GetAtt: [ GraphQlApi, Arn ]}, "types/Query/*" ]]}
Operate under the “Least Privileges Possible” principal when dealing with S3 resources. Your users should only get access to the actual files they need. A common practice is to separate the web site (which is implemented via a PublicRead S3 bucket and an Amazon CloudFront distribution) and the data files (which are in a separate S3 bucket that has higher authentication requirements).
The profilePicture Resolver
Within Serverless, we first of all need to define a function:
profilePictureResolver:
handler: graphql.profilePictureResolver
name: ${self:custom.api}-profilePictureResolver
description: AppSync Resolver for User.profilePicture
runtime: nodejs8.10
role: AWSAppSyncS3LambdaIAMRole
environment:
S3_BUCKET: { Fn::GetAtt: [ FileStorage, Arn ]}
S3_URL: { Fn::GetAtt: [ FileStorage, WebsiteURL ]}
This defines a NodeJS 8.10 AWS Lambda function that will invoke the profilePictureResolver function within the graphql.js file. It also defines some environment variables for where the resource locations are and the IAM role that will be used:
AWSAppSyncS3LambdaIAMRole:
Type: AWS::IAM::Role
Properties:
RoleName: ${self:custom.api}-AWSAppSyncS3LambdaIAMRole
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service: "lambda.amazonaws.com"
Action: "sts:AssumeRole"
Policies:
- PolicyName: S3Access
PolicyDocument:
Version: "2012-10-17"
Statement:
- Action:
- "s3:GetObject"
Effect: Allow
Resource:
- { Fn::GetAtt: [ FileStorage, Arn ]}
- { Fn::Join: [ "/", [{ Fn::GetAtt: [ FileStorage, Arn ]}, "*" ]]}
- PolicyName: CloudWatchLogsAccess
PolicyDocument:
Version: "2012-10-17"
Statement:
- Action:
- "logs:CreateLogGroup"
- "logs:CreateLogStream"
- "logs:PutLogEvents"
Effect: Allow
Resource:
- "arn:aws:logs:#{AWS::Region}:#{AWS::AccountId}:*"
To test the facility, I’m going to use the following function definition:
exports.profilePictureResolver = (event, context, callback) => {
console.log(`Invoke: event = ${JSON.stringify(event, null, 2)}`);
console.log(`context = ${JSON.stringify(context, null, 2)}`);
const response = {
url: 'http://localhost/profilePictures/foo.png',
uploadUrl: 'http://localhost/profilePictures/foo.png?upload'
};
callback(null, response);
};
This is a very simple function resolver that just returns constants, but it allows me to take a look at the event and context that is being passed in. Finally, let’s take a look at the data source definition that I have placed in the custom.appSync section of my serverless.yml file:
custom:
appSync:
dataSources:
- type: AWS_LAMBDA
name: ProfilePictures
description: Lambda function for the ProfilePictures
config:
lambdaFunctionArn: { Fn::GetAtt: [ ProfilePictureResolverLambdaFunction, Arn ]}
iamRoleStatements:
- Effect: Allow
Action:
- "lambda:invokeFunction"
Resource:
- { Fn::GetAtt: [ ProfilePictureResolverLambdaFunction, Arn ]}
This allows us to set up a test suite within the AWS AppSync console. First, navigate to the appropriate resolver definition:
- Log onto the AWS AppSync console.
- Select your API.
- Select Queries.
-
Add the following to the query window:
query Me { me { id profilePicture { url uploadUrl } } }
When you run this query, you will see the following in the output:
{
"data": {
"me": {
"id": "<random-sequence-of-chars>",
"profilePicture": {
"url": "http://localhost/profilePictures/foo.png",
"uploadUrl": "http://localhost/profilePictures/foo.png?upload"
}
}
}
}
This indicates that the Lambda function is being called and that it is returning what we expected. We can now take a look at the logs in CloudWatch:
- Open the AWS Lambda console.
- Select the
profilePictureResolverLambda function. - Select Monitoring.
- Click View logs in CloudWatch.
- Click the log group (there should only be one at this point — if not, click the latest one).
- You will see (once all the logs are expanded) something akin to this:
The only real thing to note is this: nothing from the GraphQL context is passed into the Lambda context by default. It does not know about the identity of the calling user nor the source object, both of which are required for the functionality I want to provide. You need to specify what is passed in within the request mapping template. In this case, I need $context.source and $context.identity to be passed into the AWS Lambda function:
{
"version": "2017-02-28",
"operation": "Invoke",
"payload": {
"source": $util.toJson($context.source),
"identity": $util.toJson($context.identity)
}
}
If we run the test again, we see that the payload becomes the event argument within the Lambda function. We can now move on to our simple Lambda function that generates the appropriate data:
const AWS = require('aws-sdk');
const process = require('process');
AWS.config.update({
accessKeyId: process.env.AWS_ACCESS_KEY_ID,
secretAccessKey: process.env.AWS_SECRET_ACCESS_KEY,
sessionToken: process.env.AWS_SESSION_TOKEN,
region: process.env.AWS_REGION
});
const s3 = new AWS.S3();
const expiryTime = 3600; // 1 hour = 3600 secomds
exports.profilePictureResolver = (event, context, callback) => {
const params = {
Bucket: process.env.S3_BUCKET.split(':')[5],
Key: `profilePictures/${event.source.id}.png`,
Expires: expiryTime
};
/*
** Pre-sign a getObject synchronously
*/
const response = {
bucket: params.Bucket,
key: params.Key,
region: process.env.AWS_REGION,
url: `${process.env.S3_URL}/profilePictures/${event.source.id}.png`
};
/*
** Pre-sign a putObject synchronously
*/
if (event.sourcce.id === event.identity.username) {
response.uploadUrl = s3.getSignedUrl('putObject', params);
}
callback(null, response);
};
Now, when we run the test, we get the following:
{
"data": {
"me": {
"id": "AIDAI6XOAOVZFVXXXXXX",
"profilePicture": {
"url": "http://reviews-dev-filestorage-1sylbkx8vt3ij.s3-website-us-east-1.amazonaws.com/profilePictures/AIDAI6XOAOVZFVXXXXXX.png",
"uploadUrl": "https://reviews-dev-filestorage-1sylbkx8vt3ij.s3.amazonaws.com/profilePictures/AIDAI6XOAOVZFVXXXXXX.png?AWSAccessKeyId=ASIA6BKF3YD3OMXXXX&Expires=1544657619&Signature=JfHgE2yx90pj0a5tG8tk46GYyCc%3D&x-amz-security-token=FQoGZXIvYXdzEJ%2F%2F%2F%2F%2F%2F%2F%2F%2F%2F%2FwEaDA7gVJSrhcFBjUlAJiKEAhtD2lV1GBU9sVeL%2F4x9UL2XrSe6GuGNdXDcO841uKn5h50UaInl73sCpzMV%2Fr7h8igUr5pdyqAqsDyI94XFqszfeEsBVsT25G0bjwQEKgUPYaB%2BDiYNULoco%2FL9f6EMXd%2F2y7EXEoywdJ5A%2FEtXfWe1H1XdAdnnThyoXBlcSK86yc19EJ%2FQhreSmQ%2BdMiLPaKW5lA0FoQoXBKI7jDlGWeekTcm6viPou7tzAFxnYpOqcwYLhlu6vgLe4%2BsuUjAZdDE6c%2FR2VGvbX1250YsPBdEojDRYsPcxxXhbtV24GwvDjO5pKYhhPb%2B%2BFvbMz3sHJ%2FsMFIayqABjWCRa6qkhVGIIKmkgKOv%2FxeAF"
}
}
}
}
Obviously, your data will be different. I can now do a PUT to the uploadUrl from my client using standard HTTP clients to upload a new picture. We can also use the same mechanism to generate a pre-signed URL for the getObject operation.
The Problem
You might think that this is a great way to get the profile picture. It does, however, show off one problem that is an issue with GraphQL. Let’s take an example query:
query me {
profilePicture { url }
}
This is a perfectly reasonable request — give me the download URL of my profile picture. Now, how does that affect the context of the request? The $context.source is a blank object because we are not asking for any other fields. We aren’t requesting any other fields, so nothing is passed down to the resolver of the profilePicture field. That means $context.source.id does not exist, and the URL construction will fail.
We can, of course, read the identity of the user from the $context.identity. However, this prevents us from using the same code for all profile picture requests, and the profilePicture is hooked to the User type, not the me() query. I would have to create a getProfilePicture root query to get around this. In other words, I’m adjusting my schema so that I can work around deficiencies in the way resolvers work in GraphQL.
We can fix this by converting the User queries to pipeline resolvers.
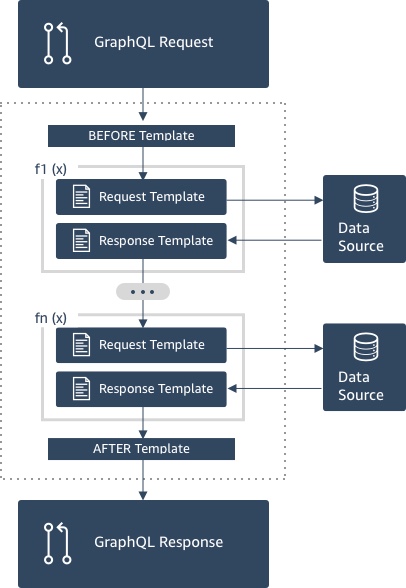
In our scenario, we would define two functions:
GetUserByIdwould take a user ID from the request and get all the data from it.GetProfilePictureForIdwould follow on from that and construct the pre-signed URLs, adding theprofilePictureobject to the previous results.
In a me query, the mapping template would populate the id with the $context.identity.username and within the getUser(id) or the Review.user query, it would populate the id field with the argument (or owner source field). This way, I can use the same functions (and the same Lambda source code) for both the me query and the getUser query.
Leave a comment